

KshemaGPT: Your AI-Powered Farming Companion for India’s Agricultural Future
KshemaGPT is a modular, multi-agent AI system designed to support Indian farmers with crop insurance, weather insights, and region-specific farming advice. Built on open-source models and fine-tuned for rural needs, it’s transforming how farmers access support.
- Buy in easy steps
- Premium Starts at INR 499
- Protect 100+ Crops
- Quick & Easy Claims
Introduction
AI is more than just a buzzword. It is a transformative technology that can change lives. At Kshema, we recognise the potential of AI and we are harnessing it to empower farmers with data-driven solutions that enhance productivity, decision-making, and provide localised support. The recent advancements in the transformer architecture and the push towards open-source Large Language Models (LLM) have made it possible to build in-house LLM solutions, leading to KshemaGPT.
What began as an internal experiment to experience and assess the question answering capabilities on a crop policy document, later became a full-scale multi-agent LLM stack built on top of multiple open-source tools. The current version of KshemaGPT can address various questions about Kshema’s crop insurance policies — Prakriti, Sukriti, Samriddhi, policy status , crop specific suggestions, etc. KshemaGPT can also offer both preventive and prescriptive suggestions regarding potential localised calamities.
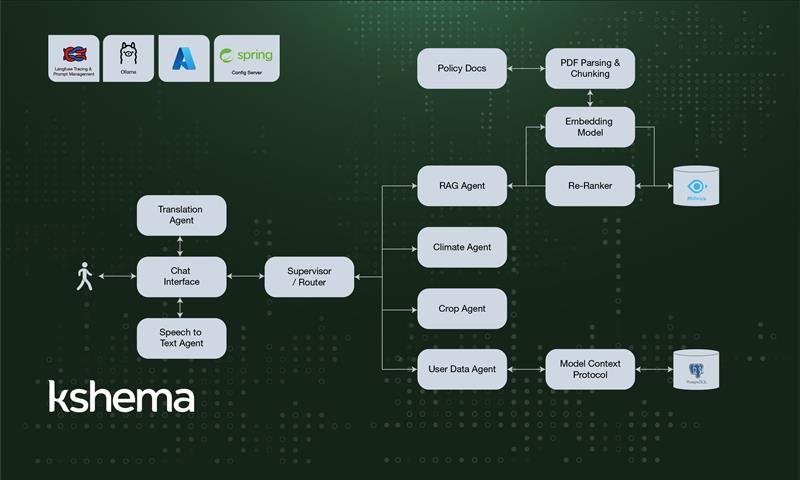
Multi-Agent Architecture
KshemaGPT leverages a multi-agent framework to handle different aspects of agricultural assistance. Each agent is designed for a specific function, ensuring modularity, efficiency, and scalability.
Initially, we started with a simple tool-calling architecture where the tools were:
- Retrieval-Augmented Generation (RAG) with Sukriti documents
- RAG with Prakriti documents
- RAG with Samriddhi documents
However, as we added more tools like User Data Agent, Crop Agent, and Climate Agent, the tool-calling approach became inefficient. This led us to switch to a hierarchy-based routing mechanism. Now, the first level of routing directs queries to one of the following:
- RAG with policy documents (Policy Agent)
- Crop Agent
- User Data Agent
- Climate Agent
Further routing is handled within each of these components, which is explained in their respective sections.
Router agent
We call it the “Supervisor”. This agent leverages Qwen-2.5 model, which we fine-tuned on a tool calling dataset. This enables the supervisor to efficiently classify and determine which of the four primary agents should handle an incoming query. The hierarchical approach has significantly improved efficiency and accuracy, ensuring that each request is routed to the most relevant module for further processing.
RAG agent
The RAG Agent enhances KshemaGPT’s responses by retrieving relevant information from a curated knowledge base before generating answers. Initially, we placed all policy documents into a single collection within the Vector DB. This approach worked well when we had a limited number of documents, but as the collection grew, we started noticing a serious issue — mis retrieval. Many policy documents share common terms, leading the system to retrieve information from the wrong policies.
To fix this, we took a structured approach:
- We created separate collections for each insurance policy (Sukriti, Prakriti, Samriddhi, etc.).
- We added a collection containing all policy documents, used only when a query involves multiple policies.
To determine which collection to retrieve from, we leveraged the tool-calling capability of Llama 3.1. Each collection is presented as a tool, and the model selects the most appropriate one based on the query. If none of the tools are called, we provide a predefined response such as, “Sorry, I do not have information to answer the question”.
This approach ensures accurate retrieval and prevents the model from generating misleading responses due to incorrect document selection. With this restructuring, retrieval precision has drastically increased, reducing errors and making policy guidance far more reliable.
PDF parsing
Parsing PDF files accurately is one of the most underrated yet critical components of building a high-quality RAG system. Policy documents, crop reports, government guidelines — most of them come in the form of PDFs. And PDFs are rarely simple. They often include complex layouts, headers and footers, background watermarks, multi-column formatting, tables, and embedded images.
We began with popular libraries like PyPDF, which worked well for clean text-based PDFs. But it quickly showed its limitations when handling more structured documents. We moved to PyMuPDF, which gave us more structured outputs like JSON and Markdown. Then we tried LLM-Sherpa, a rule-based system that specialises in identifying sections, sub-sections, and tables. This got us closer to usable structured data but still fell short when documents were less consistent.
The real bottleneck came when we encountered scanned PDFs — files that were essentially images of text. None of our earlier tools could parse these, so, we experimented with Optical Character Recognition (OCR)-based solutions. Our first pick was Qwen-2VL, an OCR model capable of generating Markdown output. It was promising but came with trade-offs: going beyond HD image resolution made it painfully slow, while reducing resolution led to poor parsing quality.
Eventually, we landed on GOT-OCR-2.0, a pruned and fine-tuned variant of Qwen-2VL. It struck the perfect balance — accurate OCR, robust layout detection — and it produced LaTeX outputs that preserved document structure exceptionally well. GOT-OCR-2.0 also excelled in extracting tables, headings, and sections, making it the most production-ready solution we tested.
In short, the PDF Parsing Agent had to evolve from being a simple text extractor to a sophisticated document understanding module. It’s the foundation that enables the RAG Agent to retrieve truly meaningful information.
Chunking
Chunking plays a critical role in the success of any RAG system. It determines how large documents are split into manageable and meaningful segments for embedding and retrieval.
In the early stages, when we used text-based parsing tools like PyPDF, PyMuPDF, and LLM-Sherpa, we tried several chunking strategies:
- Fixed token length chunking for simplicity
- Recursive character chunking for layout preservation
- Semantic chunking based on sentence boundaries
- Agentic chunking for handling multi-topic segments
Each had its limitations — either by breaking up semantically-related content or by producing overly long/short segments.
Once we moved to OCR-based PDF parsing, we were no longer dealing with plain text. We had to chunk either Markdown or LaTeX outputs, which required a different strategy altogether.
When we finally settled on GOT-OCR -2.0 for parsing, we adopted a simple rule-based approach: chunking LaTeX at section-level boundaries. While this meant that some chunks could be large, it worked well for our use case. Policy documents are usually structured with clear section headings, and keeping each section intact ensures that semantic coherence is preserved.
This approach has proven both scalable and effective in practice, giving the RAG system high-quality inputs that translate into better retrieval and generation.
Vector DB
A RAG system is incomplete without a solid Vector DB for storing and retrieving vector embeddings. When we started, we faced the classic dilemma: Which Vector DB to choose? There were numerous options, both open-source and proprietary, each with its strengths and limitations.
Our first pick was Chroma DB, mainly because of its simplicity. It was easy to set up and integrate, and we had our first version up and running in no time. However, as our dataset grew and queries became more complex, we hit two major roadblocks — persistence and scalability. Since Chroma DB is an in-memory database, it struggled with handling large datasets efficiently. Restarting the service meant losing embeddings, which was unacceptable.
We then switched to Milvus, which is arguably the most performant open-source Vector DB available today. Milvus is GPU-accelerated, supports distributed deployments, and is built specifically for large-scale vector search. It provided both the persistence and scalability we needed for a production-grade RAG system. It also integrates well with other open-source tools in the AI ecosystem.
We were using mxbai-embed-large as our embedding model when working with Chroma. It worked decently for smaller datasets but didn’t scale well as our document collection expanded. When we transitioned to Milvus, we also decided to experiment with the more sophisticated embedding model BAAI/bge-m3. The new model provided richer embeddings, leading to better retrieval accuracy.
To further refine the search results, we introduced the reranking model BAAI/bge-reranker-v2-m3, which helped us retrieve the most relevant top-k results. The reranking step significantly improved answer precision.
With Milvus, query latency dropped, retrieval quality improved, and the system became more robust. Looking back, while Chroma DB was an excellent starting point, Milvus, combined with a powerful embedding and reranking pipeline, has been the key to making KshemaGPT scalable and future-proof.





















